Indiahacks Machine Learning competition is an All India machine learning competition conducted once in a year. I participated in the qualification round and secured 6th position(out of 6000 participants), which is Top 1%. Only top 60 participants were selected to participate in offline zonal round. However, I was unable to participate in zonal round since I was traveling.
Note: Code is not production ready yet, so not sharing it on github. Will share it when I get some free time.
The challenge was to predict the segment(pos, neg) based on the given features:
- ID: unique identifier variable
- titles: format “title:watch_time”, titles of the shows watched by the user and watch_time on different titles
- genres: same format as titles
- cities: same format as titles
- tod: total watch time of the user spread across different time of days (24 hours format)
- dow: total watch time of the user spread across different days of week (7 days format)
Model Pipeline:
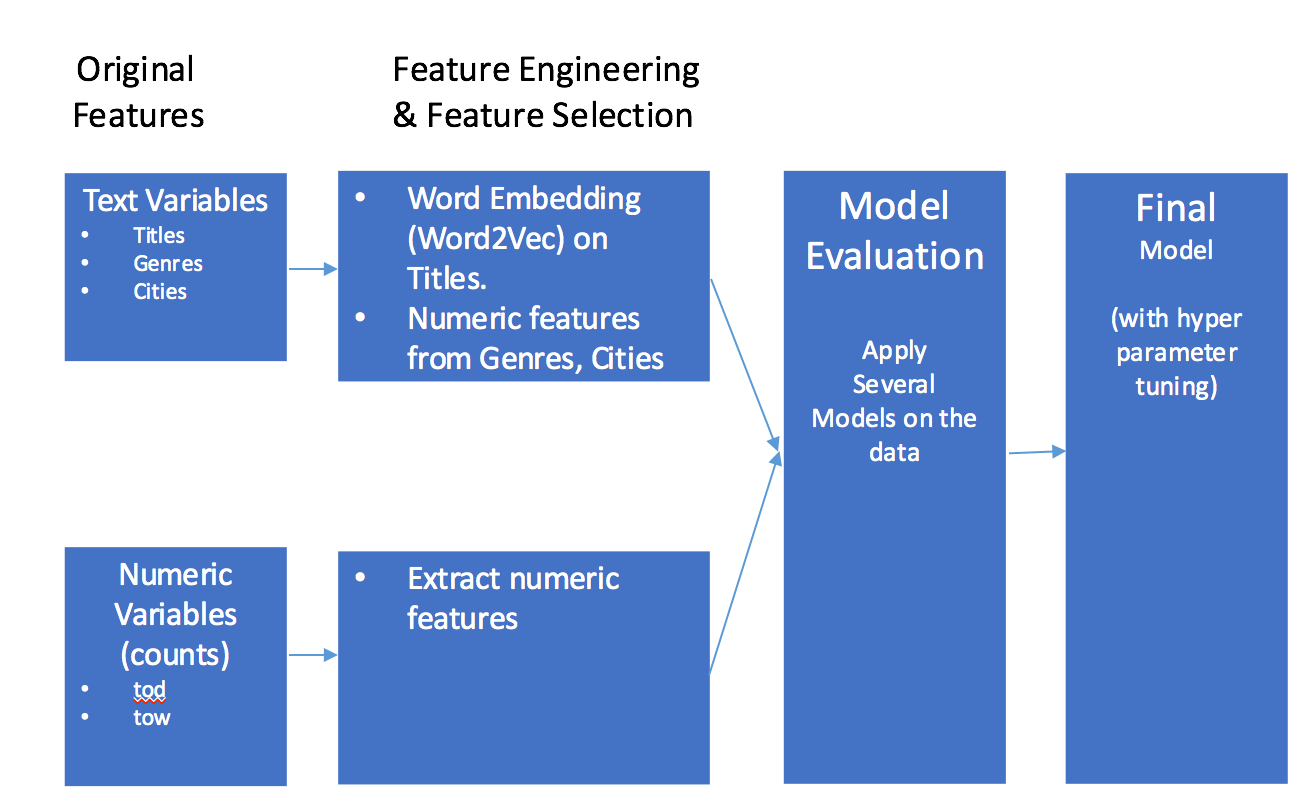
Features extracted from text variables:
Titles variable: I used word embedding using word2vec, a deep learning technique which maps similar words to context after trying Bag of Words. Word embedding improved my validation score significantly.
Tod variable: Several features were extracted from total watch time column out of which I ended up using the following features:
- tod_median_time
- tod_min_time
- dow_max_time
- watch time counts at hours (0 to 23) mapped from t0 to t23
- tod_start
- tod_end
- Days
Cities variable: Several features were extracted out of which I ended up using the following features:
- cities_min_time
- cities_count
Genres variable: Extracted the genres from this column and mapped each genre as a binary feature.
Apart from these, I extracted the following features:
- genres_min_time
- genres_max_time
- genres_mean_time
- genres_median_time
Other text related features which improved by validation score are:
- titles length
- titles count
- cities strings
Features extracted from numeric columns:
dow variable:
- Binary features for each day of the week starting from Monday to Sunday.
- Watch time spent on each day from Monday to Sunday.
Model Evaluation:
I tried several different models which produced the following scores:
| Model | Score |
|---|---|
| Logistic Regression | 0.70 |
| Linear Discriminant Analysis | 0.79 |
| K Nearest Neighbors | 0.59 |
| CART | 0.55 |
| AdaBoost | 0.79 |
| Gradient Boosting | 0.80 |
| Random Forests | 0.69 |
| Extra Trees Regressor | 0.70 |
| LightGBM(after hyper parameter tuning) | 0.822 |
| Xgboost(after hyper parameter tuning) | 0.821 |
I ended up using LightGBM to generate my predictions.
Hyper parameter tuning:
Used hyperopt to automatically find the right hyper parameters which improved my validation score for LightGBM model
The competition rewarded contestants who did feature engineering.
Things that I tried which din't work:
- Bag of Words approach.
- Dimensionality reduction on Word2vec features.
- Several extracted numerical and text features.