The data processing/feature engineering part is very important and time taking process while developing machine learning models. I usually have several different formats of data(after data processing and feature engineering) for ex: one data file may contain only normalized data, one file containing standardized data, various data files with varying features after performing feature selection. I then apply appropriate machine learning models to each of the file and see the cross validation results.
Also it is important to note that when we save a file to disk and load it back again, serialization and de-serialization happens which can impact the time.
So, the time to save the data to the disk, load the file back from the disk, memory used are very important factors that can save a lot of time for us.
Data Formats
- csv
- h5
- pytables(hdf5)
- npy
- npz
- joblib
- Todo: hickle.
- Dropped: pickle(because pickle cannot handle larger data sizes. Based on my experiments pickle format has tipping point around 2 GB).
Array Sizes
Instead of benchmarking just one size, I used asymptotic analysis approach wherein you measure the size and time of various array sizes.
- 100 x 100
- 1000 x 1000
- 10000 x 10000
- 20000 x 20000
- 30000 x 30000
- 40000 x 40000
- 50000 x 50000
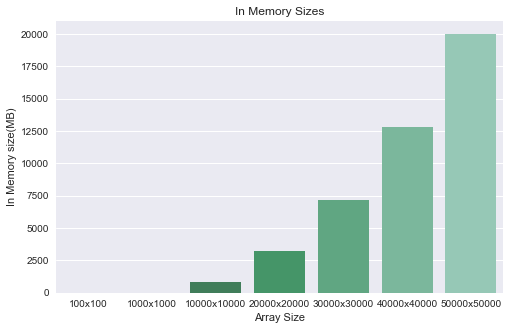
In Memory Sizes
The following table shows the size of in memory size consumed after creation of each array:
| Array Size - | In Memory(MB) |
|---|---|
| 100 x 100 - | 0.08 |
| 1000 x 1000 - | 8 |
| 10000 x 10000 - | 800 |
| 20000 x 20000 - | 3200 |
| 30000 x 30000 - | 7200 |
| 40000 x 40000 - | 12800 |
| 50000 x 50000 - | 20000 |
Lets see the same data visually:
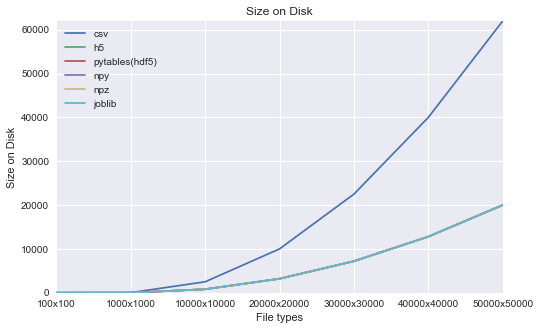
Size on disk (in MB):
- CSV format consumed the largest size on disk when compared to other data formats.
- CSV format consumes 3x the size of all other formats.
- We can see from the below chart that size of the csv file increases exponentially and way far away from other file formats.
- Surprising point is, except csv, all other file formats consume the same disk space as the memory size.
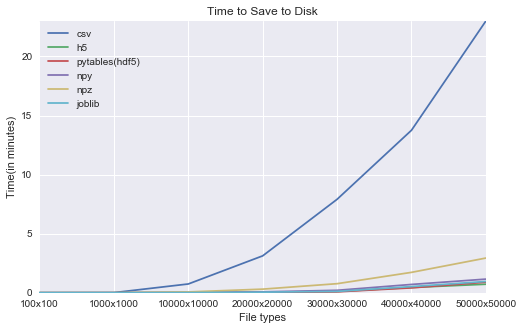
Time to save files to disk (in minutes):
- Overall, h5 and hdf5 take less time to save followed by joblib and npy and then npz.
- CSV again performed the worst.
- On an average, CSV consumes 70x times more than the least time taken by any other file format.
- As you can see from the below visual, CSV performs the worst.
- While other formats take less than a minute to save 50000 x 50000 array, csv takes approximately 23 minutes.
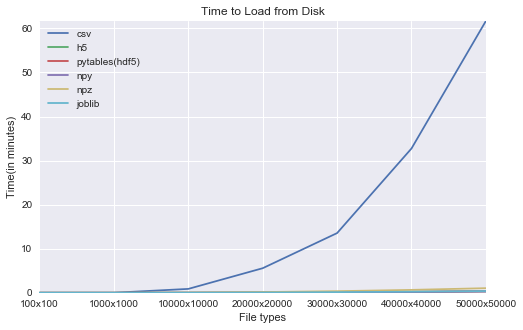
Time to load files from disk (in minutes):
- Overall npy format performs the best.
- CSV performs the worst.
- On an average, CSV consumes 140x times more than npy format to load the data from the disk.
- As you can see from the below visual, time taken to load the csv across various array sizes increases exponentially where as the other file formats show a linear pattern.
Strange results:
- During my experiments, I used memory_profiler package to check the memory size after loading each file format. I noticed strange results, sometimes the size in memory of the largest array < smaller array sizes. I have to investigate this part.